
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |
Tags
- 안드로이드스튜디오
- println()
- 참조형호출
- 자바
- 문자열
- 순환문
- dowhile문
- 타입변환
- 증감연산자
- 기본형호출
- Java
- 배열
- 변수유효범위
- for문
- 다중if
- 다차원배열
- 명명규칙
- 비트논리연산자
- array
- 삼항 연산자
- 콘솔출력문
- 단순if
- 비교연산자
- 논리 쉬프트 연산자
- print()
- 대입 연산자
- 비정방행렬
- while문
- 사용자입력Switch문
- 산술 쉬프트 연산자
Archives
- Today
- Total
신입개발자
Kafka Consumer 본문
What is
- Consumers read data from a topic (identified by name)
- Consumers know which broker to read from (Broker Discovery mechanism)
- In case of broker failures, consumers know how to recover
- Data is read in order within each paritions
- If there are too many consumers than paritions then some consumers will be inactive
Consumer Poll Behavior

while (true) {
List<Records> batch = consumer.poll(Duration.ofMillis(100));
doSomethingSynchronouslyWith(batch);
}Consumer Groups

If consumers (same group) > partitions

Offset
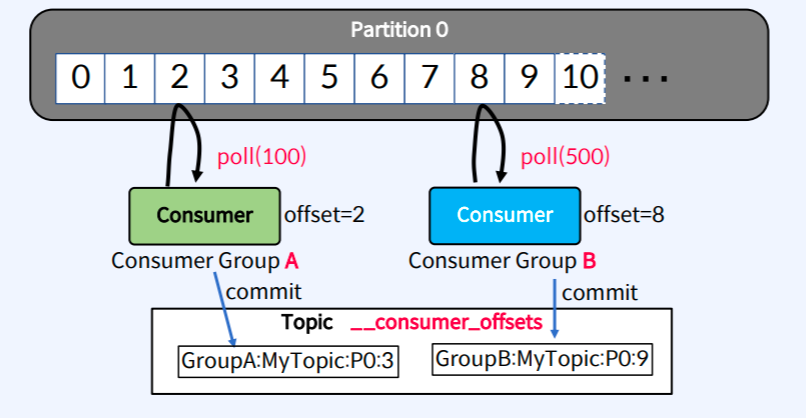
Offset Management
High watermark offset

Consumer Lag

성능: Throughput or Latency
- fetch.min.bytes (default: 1): control how many data can be send in a request. Help improve throughput and reduce number of requests, but decrease latency
- max.poll.records (default: 500): control how many messages can be received by poll request. You can increase this number if your messages are small and there is a lot of available RAM. It is also good to monitor how many records are actually being polled by request (if the number is always 500), this property value must be increase to improve throughput
- max.partitions.fetch.bytes (default 1MB): maximum data returned per partition. If there is a lot of partition to be read, you’ll have a lot of RAM
- fetch.max.bytes (default: 50MB): maximum data returned per each fetch request (between multiple partitions). Consumer can perform multiple fetches in parallel for different partitions

Consumer CLI
# read new data from a particular topic
$ ./kafka/bin/kafka-console-consumer.sh --bootstrap-server kafka2:9092
--topic sometopic
# read data from a particular topic (from the beginning)
$ ./kafka/bin/kafka-console-consumer.sh --bootstrap-server kafka2:9092
--topic sometopic --from-beginning
# read new data from a particular topic (with keys)
$ ./kafka/bin/kafka-console-consumer.sh --bootstrap-server kafka2:9092
--topic sometopic --property print.key=true --property key.separator=,
# read new data from a particular topic (and saving it in a file)
$ ./kafka/bin/kafka-console-consumer.sh --bootstrap-server kafka2:9092
> sometopic_output.txtConsumer-group CLI
# read data from a topic using consumer groups
$ ./kafka/bin/kafka-console-consumer.sh --bootstrap-server kafka2:9092
--topic sometopic --group sometopic-g1
# list available consumer groups
$ ./kafka/bin/kafka-consumer-groups.sh --bootstrap-server localhost:9092 --list
# describe a consumer group for all topics
# (here you can see offsets size, current position and lags)
$ ./kafka/bin/kafka-consumer-groups.sh --bootstrap-server localhost:9092
--group sometopic-g1 --describe
# reset the offset (to earliest) for a particular consumer group's topic
$ ./kafka/bin/kafka-consumer-groups.sh --bootstrap-server localhost:9092
--group sometopic-g1 --topic sometopic --reset-offsets --to-earliest --execute
# reset the offset (get back two positions) for a particular consumer group's
# topic
$ ./kafka/bin/kafka-consumer-groups.sh --bootstrap-server localhost:9092
--group sometopic-g1 --topic sometopic --reset-offsets --shift-by -2 --execute
# reset the offset (get back one position) for a particular consumer group's
# topic and partition
$ ./kafka/bin/kafka-consumer-groups.sh --bootstrap-server localhost:9092
--group sometopic-g1 --topic sometopic:0 --reset-offsets --shift-by -1 --executeDelivery semantics for Consumers
- at most once → auto commit mode
- at least once → Idempotent 장치 필요함.
- exactly once → kafka stream or (storing offsets outside kafka)
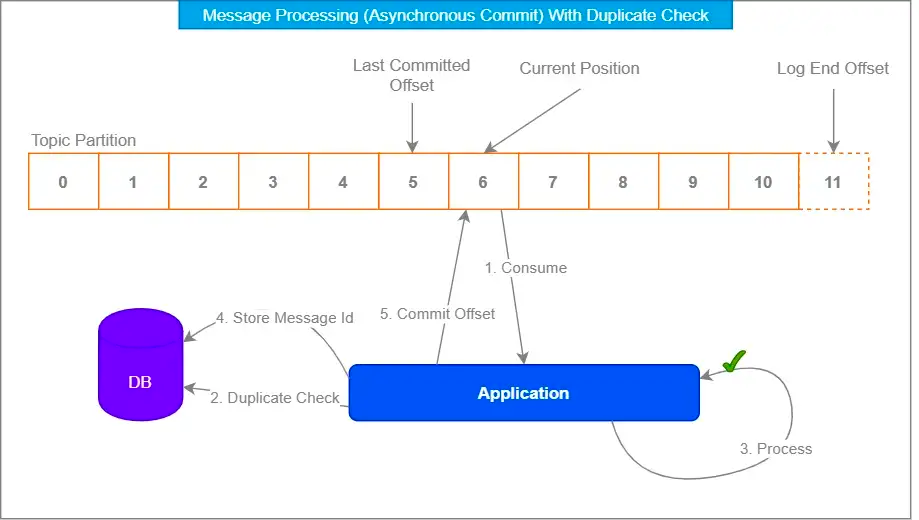
Kafka Asynchronous consumers

Consumer API
pause(partions), resume(paritions)
import org.apache.kafka.clients.consumer.Consumer;
import org.apache.kafka.common.TopicPartition;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.kafka.listener.ConsumerSeekAware;
import org.springframework.stereotype.Component;
import java.util.Collection;
@Component
public class MyKafkaListener implements ConsumerSeekAware {
@KafkaListener(topics = "myTopic")
public void listen(String message, Consumer<String, String> consumer) {
System.out.println("Received Messasge: " + message);
// Some heavy processing on message which can take time
doSomeHeavyProcessing();
// Pause consumption
Collection<TopicPartition> partitions = consumer.assignment();
consumer.pause(partitions);
// Do something while consumption is paused.
// ...
// After done, resume consumption
consumer.resume(partitions);
}
private void doSomeHeavyProcessing() {
// ... your code here
}
}
Error Handling in Consumer

- Invalid (bad) data is received from Kafka topic
- Kafka broker is not available while consuming your data
- Kafka Consumer could be interrupted
- Kafka Topic couldn’t be found
- Any exception can be happened during the data processing
- Sink system is not available
CommonErrorHandler (spring-kafka)
Here are some scenarios where implementing a custom CommonErrorHandler can be useful:
- Logging and monitoring
- Retrying message processing
- Dead-letter queues (topics)
- Error notifications
- Selective error handling
기타 참고 자료
'개인 개발 공부' 카테고리의 다른 글
| Kafka broker, controller 분리 (0) | 2023.08.31 |
|---|---|
| Kafka 고가용성 테스트 (0) | 2023.08.31 |
| Kafka Stream (0) | 2023.08.31 |
| Kafka Producer (1) | 2023.08.31 |
| Apache Kafka 설치부터 실행 (0) | 2023.08.31 |
'개인 개발 공부' Related Articles
more



Comments